Elyson Gums
Jornalista e mestre em Comunicação Social. Produzo conteúdo para projetos de SEO e inbound marketing desde 2014.
Elyson Gums

Atualizado em 08/08/2024
16 min de leitura
O Google muda mais rápido do que você consegue acompanhar? Não se preocupe, isso é comum pra muita gente.
Se inscreva na nossa Newsletter e fique por dentro das novidades de SEO.
Inscreva-se
Durante julgamento por monopólio, funcionários do Google compartilharam informações pouco conhecidas sobre como o buscador funciona; veja resumo do documento do processo, com dicas sobre SEO.
Você sabia que o Google coleta e analisa dados de cliques de página? Que custa 20 bilhões de dólares por ano para manter a Pesquisa Orgânica funcionando? Que existem sistemas pouco documentados? E que o Google “prevê” quais conteúdos são mais relevantes para cada pesquisa?
Estas e outras informações foram reveladas durante o julgamento por monopólio do Google. Elas estão em um documento de 286 páginas que conclui que a big tech pratica concorrência desleal. São várias informações sobre coleta de dados, sistema, fontes de monetização e dados de penetração de mercado.
Mas, mais do que isso: o documento é uma mina de ouro sobre SEO. Parte do trabalho de otimizar sites para mecanismos de busca é entender como o Google funciona, e o processo trouxe à tona detalhes até então inéditos.
A especialista em SEO Marie Haynes fez uma thread incrível no Twitter com vários achados interessantes do documento. Veja abaixo uma tradução dessa thread, formatada na forma de dicas práticas para você aplicar.
Algumas dicas não são realmente novas, mas agora temos perspectivas diferentes sobre elas. Outras são completamente inéditas.
Veja abaixo cada ponto em detalhes, com trechos de documentos e opiniões de Marie Haynes (e do autor deste post).
Sabemos que o Google é líder absoluto no mercado. O documento explica os motivos e traz estatísticas sobre essa dominância: não é apenas por ser o melhor buscador. Também é o mecanismo de busca padrão em vários navegadores e celulares.

Alguns números relevantes sobre isso:
Ou seja: as pessoas podem pesquisar em outro buscador, mas não o fazem.
Opinião do autor: vi muitos comentários em fóruns de SEO falando sobre “fazer SEO para o Bing” depois das quedas de tráfego por causa do HCU. Esse relatório mostra que é praticamente impossível ter escala seguindo essa abordagem. Pelo menos por enquanto quem faz SEO está “preso” ao Google, quer queira, quer não.
Outro ponto que cimenta a dominação do Google é a altíssima barreira de entrada neste mercado.
Criar e manter uma estrutura de pesquisa e anúncios como a do Google custa US$20 bilhões de dólares. 🤯

Só em 2020 o Google gastou US$11.1 bilhões para operar a estrutura de anúncios e US$8.4 bilhões em pesquisa orgânica.
No mesmo período, o Bing faturou US$7 bilhões com anúncios.
Difícil competir, né?

A relação entre Google e Apple foi um ponto de destaque durante todo o processo. Na visão da Justiça dos EUA, a relação comercial entre as empresas configura monopólio.
Se a Apple encerrasse a parceria com o Google, perderia mais de US$12 bilhões em receita. Fora os custos para desenvolver uma alternativa própria para o buscador.
O Google confirmou que “se a Apple fizesse um buscador para o Safari, causaria prejuízos”. Ou seja, é uma relação ganha-ganha entre as partes.

E se outra empresa quisesse fazer uma parceria do tipo? Segundo o documento, o Bing fez essa proposta e ofereceu 100% da receita à Apple.
A Apple recusou porque o Bing “é horrível monetizando anúncios”.

Além da monetização, outro fator que pesa contra o Bing (e possivelmente outros mecanismos de busca) é a quantidade de buscas. De acordo com o relatório, 13 meses de dados de usuários do Google equivalem a 17 ANOS de dados no Bing.

Outro ponto relevante para a configuração de monopólio é que mesmo sites especializados em busca não são competidores reais, pois gastam muito com os anúncios no Google. Exemplos que aparecem nos testemunhos são a Amazon e o booking.com.
Já as redes sociais estão no radar da big tech, em especial o TikTok. A direção da empresa reconhece que ele cresce mais do que o buscador e que isso pode representar menos tempo gasto no Google.
No entanto, em 2009 o Google estudou se o Facebook era um concorrente da Pesquisa Orgânica e descobriu que as pessoas não escolhiam um ou outro.

O documento afirma categoricamente que o Google armazena dados de usuários e os usa para melhorar a Pesquisa Orgânica. Cerca de 18 meses de dados são armazenados.

Algumas frases ditas durante os testemunhos resumem o uso desses dados:
A maioria do conhecimento que potencializa o Google, que o torna mágico, SE ORIGINA na mente dos usuários do Google. Conforme as pessoas interagem com a página de resultados de pesquisa, suas ações nos ensinam sobre o mundo. Se um documento tem reações positivas, entendemos que é bom. Se a reação é negativa, provavelmente é ruim. Em uma simplificação grosseira, essa é a fonte da magia do Google.

Marie Haynes indica ainda assistir ao vídeo abaixo, que apresenta o Knowledge Graph em 2012. Nele, engenheiros dizem que “toda a sabedoria coletiva humana que surge através do mecanismo de busca, o que as pessoas estão procurando, nos diz o que é interessante colocar em nossas bases de dados”.
Alguns algoritmos e modelos de linguagem do Google dependem de dados de usuários para funcionar, outros não. LaMDA, PaLM e PaLM2 não foram construídos com dados de usuários.
Opinião do autor: aqui na SEO Happy Hour, focamos muito na importância de produzir bom conteúdo. Não basta estar na primeira página ou tentar “hackear” o Google. No fim do dia, o engajamento das pessoas com as páginas é muito relevante. Para sucesso em longo prazo, produza conteúdo que as pessoas gostam de ler, em sites que os rastreadores do Google consigam entender facilmente.
Documentos do Google vazados em 2024 já mostravam a importância dos cliques para o Google. Durante o julgamento, isso foi confirmado. A interação dos visitantes é um critério para definir quais páginas são relevantes.
Para cada pesquisa realizada, o Google analisa vários dados, como:
O relatório explica que “com esses dados, o buscador aprende não apenas sobre os interesses dos visitantes, mas sobre a relevância dos resultados de busca e a qualidade das páginas visitadas“.

Como você verá mais adiante, os dados de cliques também alimentam diversos sistemas e sinais de classificação.
Opinião do autor: além de analisar tráfego orgânico, atente-se para os dados de engajamento do seu site. CTR, taxa de rejeição, seções engajadas, tempo médio na página, entre outros, podem explicar parcialmente os resultados do seu site em mecanismos de busca.
O Google tem sistemas complexos para definir como e quando rastrear e indexar os sites.
Sites que as pessoas gostam de visitar são indexados com mais frequência. Um exemplo prático que aparece no relatório é que um site como o The New York Times têm prioridade em relação a sites com menos visitas.
Mecanismos de busca precisam determinar em qual ordem eles rastreiam a web. Dados de usuários ajudam os mecanismos a determinar quais sites rastrear, pois permitem os buscadores a entender a popularidade relativa de vários sites. Dados de usuários também ajudam os mecanismos a determinaram com que frequência rastrear os sites.
Já na hora de indexar páginas, o Google também presta atenção às informações atualizadas. O termo em inglês é freshness, que pode ser traduzido como “frescor”. Ou seja, alguns sites precisam ser rastreados e indexados várias vezes, pois publicam informações atualizadas.
Se o Google demorasse no rastreamento deles, os visitantes perderiam informações importantes.

Opinião do autor: o exemplo do New York Times é interessante para pensar na importância de construir uma marca sólida e que as pessoas ativamente procuram. Não basta aparecer em primeiro lugar no Google, é necessário se manter lá através da criação de um domínio relevante para o seu público-alvo.
O relatório do Google menciona diversos sistemas, sinais e algoritmos do Google:
Query Based Salient Terms, ou termos salientes baseados em pesquisas, é um “sistema de memorização que ajuda o Google a entender fatos sobre o mundo”.
Ele é treinado com 13 meses de dados de visitantes.

O sistema foi apresentado em testemunho do engenheiro Pandu Nayak, em 2023. Não há muitos detalhes sobre como ele funciona.
Pandu Nayak também falou sobre o Navboost em seu testemunho e o descreveu como um dos principais sinais do Google.
Veja a descrição no documento do processo:
Navboost é outro sinal que combina pesquisas e documentos através da memorização de dados de cliques de usuários. Ele permite ao Google lembrar quais documentos os visitantes clicaram depois de fazer uma pesquisa, e a identificar quando um mesmo documento é clicado em resposta a múltiplas pesquisas. Antes de 2017, o Google treinou o Navboost com 18 meses de dados de usuários. Desde então, treina o Navboost em 13 meses de dados de usuários.

Detalhe: tem e-mails internos do Google mostrando certo descontentamento com o poder e relevância do Navboost. 👀
Na sequência, o relatório apresenta sistemas que não dependem tanto de dados de usuários. Eles complementam algoritmos como Navboost ou o QBST.
O relatório apresenta:
Cada um tem suas particularidades, mas eles cumprem basicamente o mesmo propósito:
Conhecidos como sistemas de “generalização”, esses sinais “podem não ser tão bons em memorizar fatos, mas são muito bons em entender a linguagem”. Eles foram “desenhados para preencher lacunas em dados de cliques”; ajudam o Google a fazer generalização de situações onde tem dados, para situações onde não têm.

Marie Haynes resume da seguinte forma: Sabe como os Modelos de Linguagem de Larga Escala (LLMs) preveem a próxima palavra em uma frase? Esses sistemas são feitos para prever qual conteúdo mostrar a um visitante.
A performance do MUM é praticamente humana ao identificar padrões de linguagem. Já o RankBert não é tão bom nisso.

Esse tipo de sistema não substitui os algoritmos treinados com dados de visitantes.
Como você viu, o Google faz uso intenso de Inteligência Artificial, por meio das LLMs. Isso se intensificou a partir de 2015, com o objetivo de tornar o Google menos dependente de dados de visitantes e ainda assim melhorar a classificação de páginas.
Veja exemplo prático de como isso acontece, presente no relatório:
Por exemplo, a tecnologia de IA acelerou a qualidade de pesquisa a respeito de corrigir erros de digitação ou conceitos semanticamente relacionados, sem necessitar de dados de usuários.

Apesar disso, sistemas de IA não são suficientes para determinar qualidade. Nas palavras de Marie Haynes, “o Google precisa continuar aprendendo com os visitantes”.
A IA generativa não (ou pelo menos ainda não) eliminou ou reduziu significativamente a necessidade de usar dados de usuários para entregar resultados de qualidade. […] Quando solicitado para prever como mecanismos de busca funcionarão daqui a cinco ou dez anos, o Engenheiro de Software ex-Google Eric Lehman atestou que embora possa diminuir no futuro, sempre haverá um papel para dados de usuários. Isso é em parte porque “sistemas de aprendizagem profundo são muito difíceis de entender”.

Opinião do autor: As Inteligências Artificiais já estão transformando a Pesquisa Orgânica. Mas, quando você pensar nos impactos disso para SEO, vá além do “escrever textos usando ChatGPT” ou “AI Overview vai roubar tráfego de sites”. A discussão é bem mais densa e, quando você se aprofunda nela, fica mais fácil entender como trabalhar com eficiência. Exemplo simples: se você sabe que o Google tem sistemas avançados de semântica, não faz sentido repetir palavras-chave exatas o tempo todo no texto.
A maior parte da receita do Google vem de anúncios. Existem dois tipos principais: listagem de produtos e anúncios em texto. Os anúncios em texto são responsáveis por 80% da receita de Pesquisa.
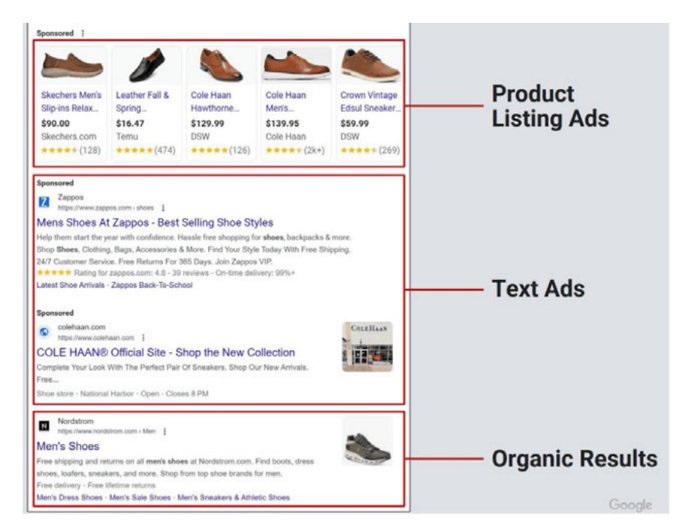
Isso é relevante para o processo de monopólio porque o argumento da Justiça dos EUA é que anunciantes não podem se dar ao luxo de sair do Google. E a big tech usa isso a seu favor para testar diferentes formas de precificação.
Uma ação polêmica foi passar a considerar erros de digitação como parte da correspondência ampla no Google Ads. Isso encareceu os anúncios, o que levou 25% dos anunciantes a excluírem a opção na configuração de campanhas. Na sequência, o Google proibiu anunciantes de rejeitarem a função.

O argumento do Departamento de Justiça é que isso é concorrência desleal, pois só é possível pois o Google exerce monopólio sobre pesquisas.
Opinião do autor: na correria do dia a dia nem todo mundo para pra pensar nisso, mas SEO e mídia paga são duas faces da mesma moeda. A qualidade de Pesquisa Orgânica é fundamental para as pessoas usarem o Google, e a mídia paga abastece financeiramente a estrutura. Quando você pensa nisso, fica mais simples entender as decisões do Google sobre temas como conteúdo útil ou políticas antispam.
Ao final da thread, Marie Haynes fez uma avaliação bem pertinente sobre o processo e as informações contidas no relatório do processo.
Veja abaixo uma tradução na íntegra:
O Google é um bom mecanismo de busca. Sim, eles fazem monopólio. E isso vai ser ainda mais importante enquanto a IA se desenvolve. Sim, eles enfrentam problemas enquanto a IA se desenvolve. É um processo de aprendizado.
A missão do Google é organizar a informação do mundo e torná-la universalmente acessível. Fico pensando como no futuro vamos dar risada da época em que a gente apertava botões de plástico com os dedos para encontrar informação. Um dia, tudo isso será acessível a partir dos nossos pensamentos. É muito importante que o Google continue a melhorar.
O Google deveria ter competição? Sim. Mas não acho que alguém será capaz de fazer melhor do que eles.
Estou interessada em ver o que acontece com o mecanismo de busca do ChatGPT. Eu acho que eles podem oferecer uma alternativa viável. Mas depois de ler esse documento não tenho certeza se eles sequer conseguem competir a menos que se tornem o padrão ao qual as pessoas recorrem.
O Google não é perfeito, mas a realidade é que são a fonte para a qual a maioria das pessoas recorre para obter informação. Espero que eles possam se tornar uma fonte de verdades agora que estamos entrando em uma era onde muita desinformação será espalhada.
__
Se você chegou até aqui: muito obrigado!
Guardei uma pérola especialmente pra quem leu até o fim: o termo mais pesquisado no Bing é google.com.
É aquela história que a gente já conhece, de que a função do Internet Explorer é baixar o Firefox. Mas é engraçado ler isso na documentação de um dos processos mais importantes da história recente dos EUA.

Gostou desse texto? Então você também vai adorar a newsletter e podcast da SEO Happy Hour. Siga a gente no LinkedIn para não perder as atualizações!

Jornalista e mestre em Comunicação Social. Produzo conteúdo para projetos de SEO e inbound marketing desde 2014.
14/03/2025
28/02/2025
27/02/2025
Comentários