Elyson Gums
Jornalista e mestre em Comunicação Social. Produzo conteúdo para projetos de SEO e inbound marketing desde 2014.
Elyson Gums
Atualizado em 24/02/2025
5 min de leitura
O Google muda mais rápido do que você consegue acompanhar? Não se preocupe, isso é comum pra muita gente.
Se inscreva na nossa Newsletter e fique por dentro das novidades de SEO.
Inscreva-se
Sem o Googlebot, SEO não funciona. Ele é o robô do Google que faz o rastreamento de URLs para que elas possam aparecer nos resultados orgânicos.
Ele é um programa que roda nos servidores do Google e analisa o seu conteúdo, relata erros de rede, redirecionamentos, e outros detalhes que possam prejudicar a visibilidade das páginas.
Martin Splitt, porta-voz do Google, e Gary Illyes, engenheiro do buscador, compartilharam em um blog post os detalhes sobre como o robô funciona. Veja os principais pontos traduzidos abaixo.
Rastreamento é o processo de baixar o conteúdo de páginas já existentes ou recém-descobertas. Esse trabalho é feito por crawlers (também chamados de rastreadores, robôs, spiders, etc.), como o Googlebot.
Em resumo, acontece assim:
Se estiver tudo certo, o rastreamento acontece. Depois dessa etapa, o Google decide se a página será indexada ou não. Inclusive, parte do trabalho de SEO é tornar o site otimizado para que este processo ocorra sem erros.
A versão de página que o robô acessa é bem diferente da que aparece para os humanos. Para ele, o principal aspecto é o código-fonte, incluindo HTML, JS e CSS.
Apesar de ver versões diferentes de página, o Googlebot acessa os sites de forma parecida com um ser humano.
Quando alguém abre um site no navegador, o processo que acontece nos bastidores é o seguinte:
Quando o Googlebot abre um site, faz parecido:
Ou seja, é um processo parecido, mas otimizado para rastrear uma infinidade de páginas diariamente.
Alguns detalhes relevantes do processo:
Crawl budget é a “cota de rastreamento” de um site. Significa basicamente a quantidade de páginas e recursos que o Googlebot consegue acessar. Quando passa da cota, ele para o processo e retoma posteriormente.
Por isso, donos de sites precisam gerenciar quais recursos são rastreados e como eles influenciam o crawl budget. É um ponto a se considerar apenas para sites grandes, com milhares de páginas, e deve ser feito com apoio de profissionais em SEO e desenvolvimento.
Algumas boas práticas recomendadas por Martin Splitt e Gary Illyes são:
Existem duas formas de saber quais páginas o robô está visitando: seus logs de servidor e o Google Search Console.
Nos logs de servidor, você verá todas as URLs que foram requisitadas por servidores e rastreadores, aí, é só buscar os IPs do Google.
Já no Google Search Console, basta acessar o relatório de estatísticas de rastreamento. Ele apresenta todas as páginas e recursos rastreados. E também mostra:
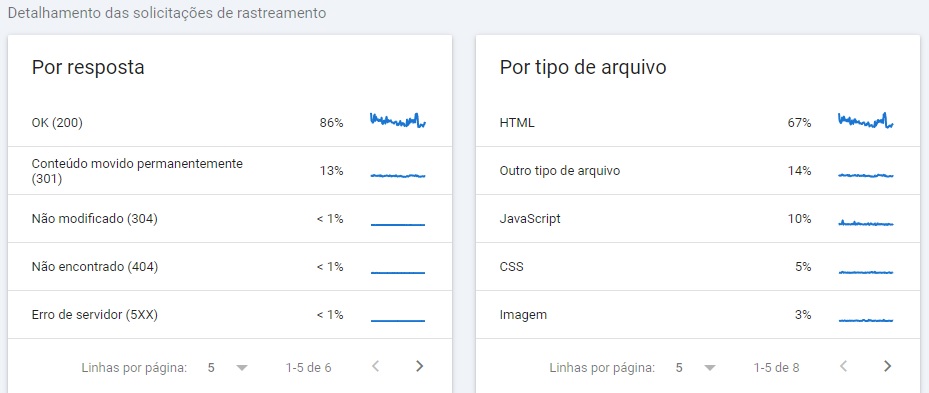
__
Martin Splitt e Gary Illyes estão publicando semanalmente novos artigos com alguns detalhes técnicos sobre como o Googlebot funciona. E você acompanha tudo por aqui! Siga-nos no LinkedIn e no YouTube, acompanhe nossa newsletter e podcast e não perca nada.

Jornalista e mestre em Comunicação Social. Produzo conteúdo para projetos de SEO e inbound marketing desde 2014.
28/02/2025
27/02/2025
09/12/2024
Comentários